Perché Git è il version control più amato dagli sviluppatori

Introduzione
Alla luce della recente acquisizione da parte di Microsoft di GitHub per la bellezza di 76 miliardi, le menti più curiose si saranno sicuramente poste la domanda: “Perché?”.
Nel seguente articolo parleremo di Git spiegandone la filosofia, lo paragoneremo al suo diretto competitor Microsoft Team Foundation Version Control (TFVC) e analizzeremo come poter gestire un progetto complesso in maniera semplice ed indolore grazie alle caratteristiche che rendono Git la tecnologia scelta per il version control da milioni di sviluppatori.
Specifichiamo sin da subito che questo articolo si pone l’obiettivo di analizzare ad alto livello come le varie tecnologie vengono utilizzate più comunemente, non si andrà perciò nel dettaglio di ogni possibile configurazione di esse.
L’articolo si rivolge inoltre a persone del mestiere che sono abituate a lavorare in ambito Microsoft con TFVC.
Cos’è Git?
Quando è necessario gestire un progetto mantenendo il controllo del codice sorgente e della sua storia ed è necessario permettere a più sviluppatori di collaborare su di esso, ci vengono in aiuto i sistemi di version control.
Nel tempo vari competitor hanno portato al pubblico la loro proposta (troppi da poterli riportare qui), ma lo standard di facto nella comunità open source è ormai diventato Git.
Creato nel 2005 da Linus Torvald per lavorare al kernel Linux e manutenuto da Junio Hamano (uno sviluppatore di Google) da due mesi dopo la sua creazione, Git è in continua evoluzione e completamente gratuito ed open source.
Noiosa storia a parte, procediamo ora con la parte più interessante: perché dovrei preferirlo ad altri sistemi di versionamento?
GIT vs TFVC
Prima di buttarci a capofitto nella descrizione delle principali differenze tra i due sistemi, chiariamo subito un concetto fondamentale.
Spesso, nel campo IT, non esiste una soluzione “migliore”, ma solo una soluzione più adatta alla situazione corrente. Piuttosto che schierarsi da una parte o dall’altra, lo sviluppatore più esperto deve analizzare i pro e i contro di ogni soluzione possibile e scegliere quella più adatta al problema che ha di fronte.
Questo significa che la seguente digressione non ha scopo di dichiarare un vincitore tra le due tecnologie, ma solamente di evidenziare quali sono i pregi e i difetti delle due tecnologie a confronto per permettere a tutti di prendere la decisione più adatta alle proprie esigenze.
Chiarito questo concetto, passiamo ad analizzare le due tecnologie.
Sistemi Centralizzati e Sistemi Distribuiti
La principale differenza tra i due sistemi è proprio la filosofia alla base di essi, quella che regola dove e come il codice debba essere conservato e storicizzato. TFVC è infatti un sistema centralizzato, mentre Git è un sistema distribuito.
Proviamo a spiegare nel modo più semplice possibile le differenze tra i due.
Un sistema centralizzato prevede un repository centrale che possiede l’autorità totale su tutto ciò che è possibile fare e non fare da parte di chi si connette ad esso.
L’esempio più comune di questo (sicuramente vi sarà capitato se avete lavorato con TFVC in passato) è la possibilità di attivare l’estrazione esclusiva dei file.
Se un nostro collega sta lavorando su un file, questo rimarrà leggibile da tutti, ma non sarà possibile a nessun altro modificarlo fino a che la persona che lo ha estratto per primo non annullerà o invierà al server le sue modifiche.
Questo utile meccanismo permette di evitare complicazioni future con i merge del file in questione ma, come dicevamo poco fa, non è detto che sia sempre un effetto desiderato.
Un sistema distribuito, invece, pur mantenendo sempre un repository centrale permette a chiunque debba lavorarci di crearsi (clonarsi) un proprio repository locale completo al 100% e completamente separato dallo stato e dalle regole di quello centrale.
Ovviamente nel sincronizzarsi con quello centrale anch'esso dovrà sottostare a delle regole, ma fino a che si sviluppa nel proprio repository locale si è liberi di fare ciò che si vuole.
Per riprendere l’esempio di prima, non avrà più senso un meccanismo di estrazione esclusiva di un file poiché ogni repository locale avrà una sua copia del file stesso separata da quello sul repository centrale e con una propria storia.
Questo meccanismo richiede di conseguenza una maggiore attenzione sui merge, perché si potrebbero avere dei file completamente diversi tra loro.
Aggiungo un piccolo aneddoto per evidenziare un'altra conseguenza del sistema distribuito.
Qualche tempo fa mi trovavo da un cliente con, purtroppo, un limitatissimo accesso ad internet che mi impediva di raggiungere il server contenente il codice sorgente.
Con un sistema centralizzato mi sarei ritrovato a dover lavorare offline, senza tracciare le mie modifiche in alcun modo e dovendo poi ricollegare la mia soluzione e fare un unico grande check-in una volta avuto nuovamente accesso alla rete.
Tralasciando il pericolo hardware (le modifiche si sarebbero trovate solamente sul mio pc), l’idea di avere un unico check-in perdendo completamente la storia di ciò che era accaduto durante lo sviluppo avrebbe potuto causare numerosi problemi.
Chi non si è mai sentito chiedere da un cliente di riattivare una funzionalità cancellata il giorno prima?
Fortunatamente, il progetto in questione si avvaleva di un sistema distribuito (Git).
Questo non ha certamente eliminato il pericolo hardware, ma è stato fantastico non dovermi preoccupare di non poter fare check-in intermedi.
Ricordate quando ho scritto che il repository locale è al 100% un repository anche da solo? Lo intendevo veramente!
Su ogni repository locale è possibile fare check-in (chiamati commit su Git) locali, mantenendo una storia completa del proprio codice anche senza nessuna necessità di comunicare con quello centrale.
Non solo, quando si andrà a riportare le modifiche effettuate localmente anche sul repository centrale, la storia verrà completamente mantenuta e sarà possibile utilizzare una versione precedente del nostro repository locale anche lì.
Per quella situazione, un sistema distribuito era quindi una scelta perfetta.
Altre differenze
Le differenze tra i due sistemi non finiscono qui.
Un’altra fondamentale differenza risiede in “cosa” viene versionato.
Normalmente, collegando la propria solution a TFVC, ad essere versionati saranno tutti gli elementi inclusi nella soluzione stessa.
È possibile quindi includere ed escludere elementi dai vari progetti per gestirne il versionamento.
Git ragiona invece diversamente.
Ad essere versionata, o meglio a costituire il repository, è l’intera cartella scelta in fase di clonazione del repository centrale. Questo vuol dire che ogni file presente nella cartella, a prescindere dall’essere incluso o meno nella soluzione, verrà versionato.
Questo è un vantaggio in caso si vogliano inserire altri file senza che facciano necessariamente parte della soluzione, ma può creare anche molto “rumore” quando invece ad essere versionati sono file che non ci interesserebbe versionare (pensiamo ad esempio a tutti i file nelle cartelle di build dei progetti).
A venirci in soccorso è uno speciale file di cui Git tiene conto, il “.gitignore”.
Questo file non è nient’altro che un semplice file di testo, contenente una serie di nomi file, path (interi o parziali) ed estensioni che Git deve ignorare.
Ad esempio una riga con scritto “*.dll” dirà a Git di ignorare tutti i file con estensione .dll, che non verranno quindi più versionati.
Nelle ultime versioni di Visual Studio, fortunatamente, la creazione del gitignore è automatica ed esso contiene già tutte (o quasi) le regole di cui potremmo avere bisogno per utilizzare Git senza problemi.
Le due tecnologie differiscono anche nella modalità con cui come gestiscono il branching.
Anche se non sembra, lo abbiamo già accennato poco fa!
Creare un branch con TFVC significa creare un’altra copia perfetta e completa del repository.
Normalmente questo non costituisce un problema, ma se la strategia di gestione del progetto richiede numerosi branch, lo spazio occupato inizierà ad aumentare esponenzialmente.
Git, dal canto suo, si limita invece a creare un nuovo flusso di commit che partono dal quel punto specifico. Questo gli permette di salvare solamente i delta delle modifiche effettuate, risparmiando spazio di archiviazione.
In un’azienda dove si hanno molti progetti con più branch a progetto il risparmio di spazio inizia a diventare molto evidente.
Inoltre, il flusso di commit separato verrà mantenuto anche dopo il merge, esattamente come dicevamo poco fa.
Esistono anche altre differenze (come la gestione delle pull request), ma in questo momento esulano dallo scopo di questo articolo.
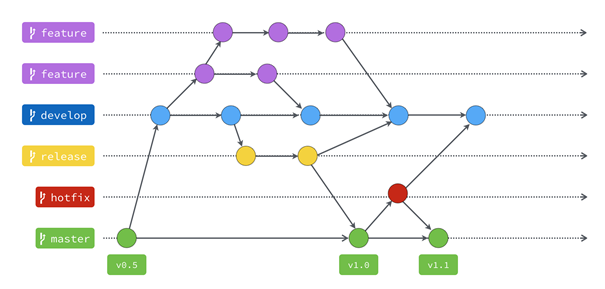
Git Flow
Tutte le caratteristiche descritte in precedenza portano lo sviluppatore a gestire il proprio repository attraverso un ampio utilizzo di branch.
Git non è tuttavia perfetto, ed una cattiva gestione dei branch può portare ad una situazione insostenibile dei merge. Capita a tutti infatti, almeno una volta, di trovarsi in una situazione in cui Git non ti permette di fare commit poiché non disponi dell’ultima versione, ma non puoi scaricare l’ultima versione perché hai delle modifiche in sospeso!
Senza entrare troppo nel dettaglio, Git si aspetta la versione da cui è partito il branch per poter effettuare il merge, ma se gli stessi file vengono modificati da qualcun altro che è più rapido di noi nel farlo sul ramo principale, ecco che Git non ha più ben chiaro cosa fare.
Per porre rimedio a questo tipo di problematiche sono stati ideati vari stratagemmi, tra cui quello che ci interessa: Git Flow.
Git Flow (ormai distribuito automaticamente nel pacchetto di Git) non è altro che un flusso organizzativo dei branch, dei loro scopi e delle loro funzioni.
Tutto parte da un ramo principale, chiamato Master, che è il ramo che rappresenta il codice attualmente in produzione. Questo ramo non va mai modificato manualmente, da nessuno.
C’è poi il ramo Develop, quello di sviluppo, parallelo al ramo Master e anch’esso da non modificare a mano.
Come inserire allora le modifiche necessarie?
Ogni funzionalità dovrebbe essere inserita nel ramo Develop attraverso la creazione di un Feature branch.
Il Feature branch non è altro che un ramo che parte da Develop ed in esso viene riunificato al termine della modifica sul codice.
Il team di sviluppo aprirà e chiuderà quindi tutti i Feature branch necessari per implementare tutte le funzionalità del progetto.
Una volta terminato lo sviluppo, il codice è pronto per essere messo in collaudo.
Viene quindi creato un ramo Release, che parte da Develop.
Eventuali modifiche emerse durante il collaudo vengono applicate ad esso, dopodiché anche questo ramo viene chiuso. La particolarità dei Feature branch è che, una volta chiusi, essi si andranno a riunire automaticamente sia in Develop che in Master.
In questo modo la nostra versione del codice, pronta per il rilascio in produzione, sarà identica su entrambi i principali rami di sviluppo (Develop e Master).
Come nota aggiuntiva, in caso di problemi in produzione da sistemare immediatamente senza poter attendere l’intero normale iter di sviluppo sono affrontabili con la creazione di una speciale tipologia di branch, chiamata Hotfix, che una volta chiusa si riunirà anch’essa sia in Master che in Develop.
Seguendo questo schema di sviluppo fedelmente si evitano la maggior parte delle complicazioni dovute ai merge e si mantiene un flusso sufficientemente solido.
È inoltre da segnalare la comodissima estensione “GitFlow” per Visual Studio che permette di gestire tutto questo direttamente dalla sezione “Team Explorer” dell’IDE Microsoft.
In alternativa bisogna usare GUI di terze parti (come le famose GitKraken, SourceTree, ecc.) o la cara vecchia linea di comando.
Qui sotto uno schema riassuntivo del flusso di Git Flow, perché a volte un’immagine spiega meglio di mille parole.